

非递减子序列
这里是要求所有的非递减子序列,和之前的组合问题类似,但这里不能对数组进行排序。
所以这里的去重逻辑和之前都不一样。
首先是和之前的子集问题一样,可以不加终止条件,不过按照题意至少拥有两个元素,所以当我们的 path 大于等于 2 时,才将其加入到 ans 中。
单层的搜索逻辑: 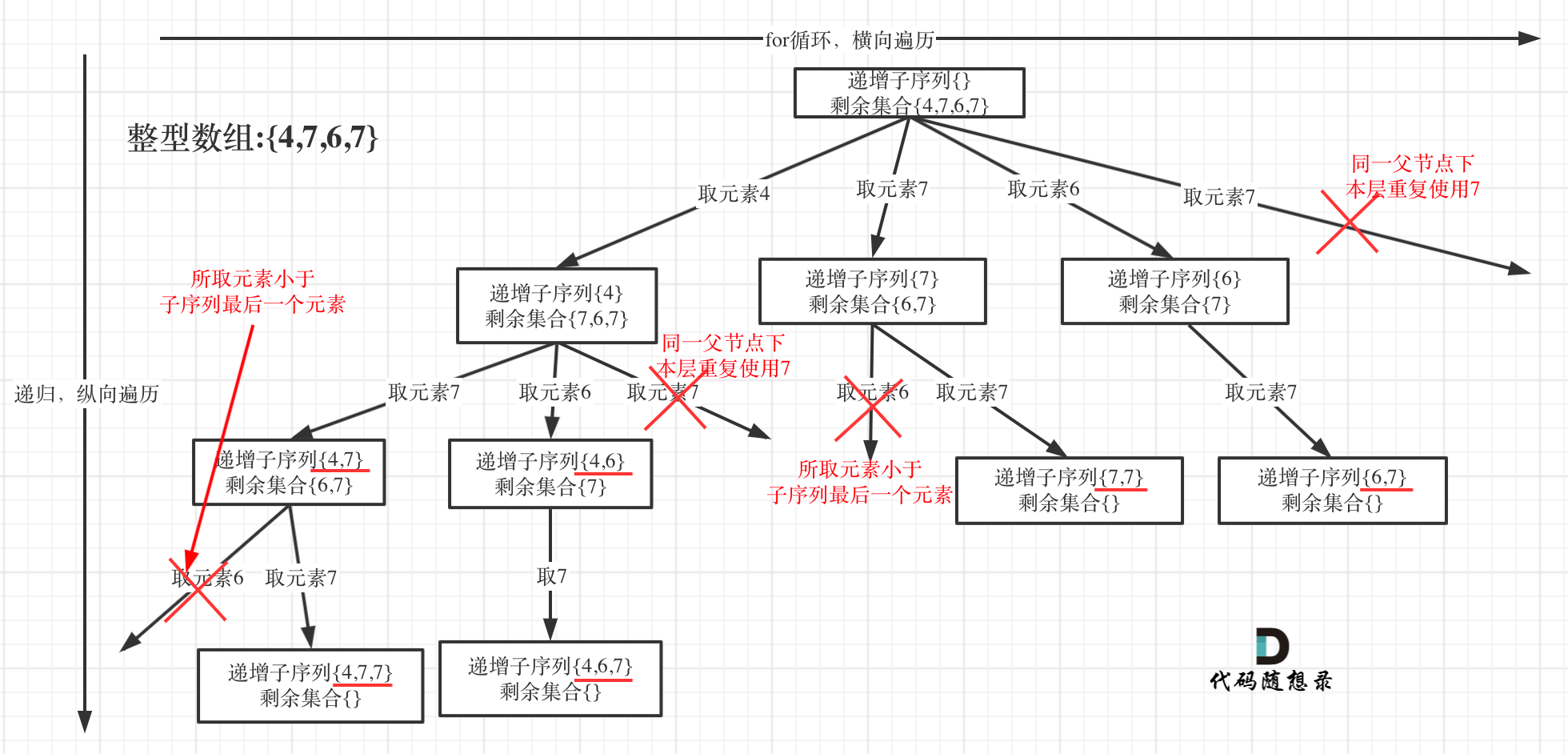
如果我们转换成树状图,可以发现,在同一层(也就是 for 循环中)中,已经用到的元素就不能再用了,而我们可以使用一个 set 来存储已经用过的元素,来达到去重的效果。
整体的代码如下:
class Solution {
private:
vector<int> path;
vector<vector<int>> ans;
void backTracking (vector<int>& nums, int startIndex) {
if (path.size() >= 2) { // 当path长度大于等2时才加入结果集
ans.push_back(path);
}
unordered_set<int> used; // 使用set来对同一层的元素进行去重
for (int i = startIndex; i < nums.size(); i++) {
// 当path不为空且当层遍历的元素小于path中最后一个元素,就跳过
if (!path.empty() && nums[i] < path.back()) continue;
// 当遍历的元素存在set中,说明之前已经用过该元素,跳过
if (used.find(nums[i]) != used.end()) continue;
used.insert(nums[i]);
path.push_back(nums[i]);
backTracking(nums, i + 1);
path.pop_back();
}
}
public:
vector<vector<int>> findSubsequences(vector<int>& nums) {
path.clear();
ans.clear();
backTracking(nums, 0);
return ans;
}
};全排列
由于是求排列,因此在每一层的 for 循环中,我们都要遍历所有的元素,除了已经使用过的元素。
因此处理的逻辑其实可以和非递减子序列一样,使用一个 set 来存储已经使用过的元素。或者是使用 find 来判断是否已经使用过。
总体代码如下:
class Solution {
private:
vector<int> path;
vector<vector<int>> ans;
void backTracking(vector<int>& nums) {
if (path.size() == nums.size()) { // 当路径长度等于数组长度时,找到一个排列
ans.push_back(path);
return;
}
// 注意因为求排列,所以i从0开始,以遍历所有的元素(除了已经使用过的)
for (int i = 0; i < nums.size(); i++) { // 遍历每个数字
if (find(path.begin(), path.end(), nums[i]) != path.end()) continue; // 如果数字已经在路径中,跳过
path.push_back(nums[i]); // 选择数字
backTracking(nums); // 递归
path.pop_back(); // 撤销选择
}
}
public:
vector<vector<int>> permute(vector<int>& nums) {
path.clear();
ans.clear();
backTracking(nums);
return ans;
}
};当然这里也可以使用一个 used 数组来标记是否使用过,代码如下:
class Solution {
private:
vector<int> path;
vector<vector<int>> ans;
// 使用used数组的方式
void backTracking(vector<int>& nums, vector<bool>& used) {
if (path.size() == nums.size()) { // 当路径长度等于数组长度时,找到一个排列
ans.push_back(path);
return;
}
// 注意因为求排列,所以i从0开始,以遍历所有的元素(除了已经使用过的)
for (int i = 0; i < nums.size(); i++) {
if (used[i] == true) continue; // 如果数字已经在路径中,跳过
used[i] = true; // 标记为已使用
path.push_back(nums[i]);
backTracking(nums, used);
path.pop_back();
used[i] = false; // 回溯时撤销标记
}
}
public:
vector<vector<int>> permute(vector<int>& nums) {
path.clear();
ans.clear();
vector<bool> used(nums.size(), false); // 初始化used数组
backTracking(nums, used);
return ans;
}
};全排列 II
这里与全排列的区别在于,数组中可能存在重复的元素,因此我们需要对同一层的元素进行去重。
去重还一定要对元素进行排序,这样我们才方便通过相邻的节点来判断是否重复使用了。
我们对同一树层,前一位(也就是 nums[i-1] )如果使用过,那么就进行去重。
总体的代码如下:
class Solution {
private:
vector<int> path;
vector<vector<int>> ans;
void backTracking(vector<int>& nums, vector<bool>& used) {
if (path.size() == nums.size()) { // 当路径长度等于数组长度时,找到一个排列
ans.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) { // 遍历每个数字
// used[i - 1] == true,说明同一树枝nums[i - 1]使用过
// used[i - 1] == false,说明同一树层nums[i - 1]使用过
// 如果同一树层nums[i - 1]使用过则直接跳过
if (used[i]) continue; // 如果数字已经被使用,跳过
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) continue;
used[i] = true; // 标记数字为已使用
path.push_back(nums[i]); // 选择数字
backTracking(nums, used); // 递归
path.pop_back(); // 撤销选择
used[i] = false; // 取消标记
}
}
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
path.clear();
ans.clear();
vector<bool> used(nums.size(), false); // 用于标记数字是否被使用
sort(nums.begin(), nums.end()); // 排序以便去重
backTracking(nums, used);
return ans;
}
};去重条件对于这个去重条件
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) continue;,我们可以理解为: 在当前层中,如果我们遇到了两个值相同的元素,而前一个还没被用(说明它在当前层的某个位置被跳过了),那我们就不应该再用当前这个重复值了。也就是说:
如果在当前层我们还没选过
nums[i - 1],那就不应该再选nums[i](因为它俩相等);如果我们已经选过了
nums[i - 1],说明当前这条路径在“不同树枝”上,可以选nums[i]。
在去重的代码中,我们可以看到 used[i - 1] 的判断条件,这里是为了避免在同一树层中,使用了相同的元素。
如果改成 used[i - 1] == true, 也是正确的。如果要对树层中前一位去重,就用 used[i - 1] == false,如果要对树枝前一位去重用 used[i - 1] == true。
对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高。
这里以随想录中的所举的例子 [1, 1, 1] 为例1:
- 树层上去重:
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) continue; 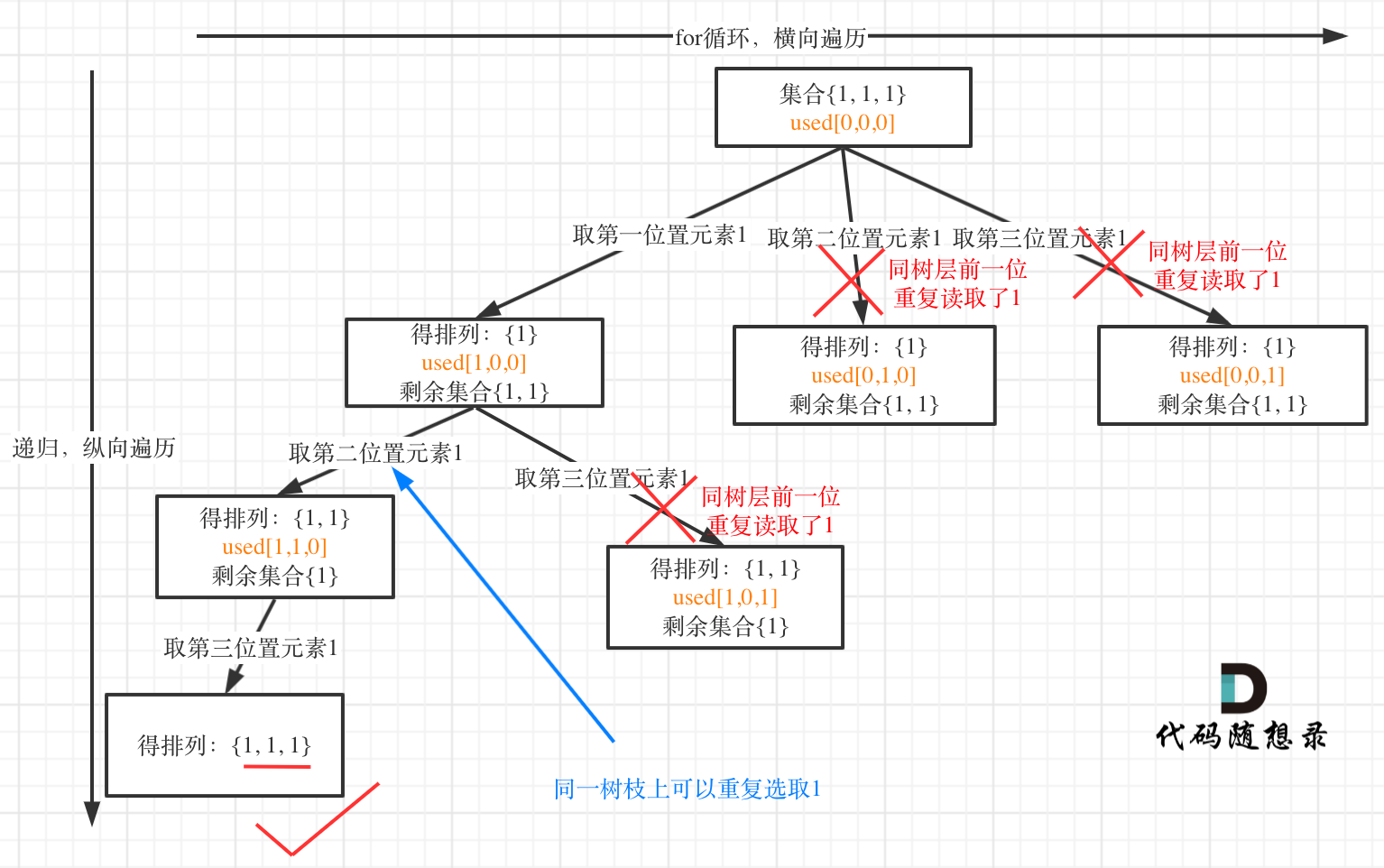
- 树枝上去重:
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1]) continue; 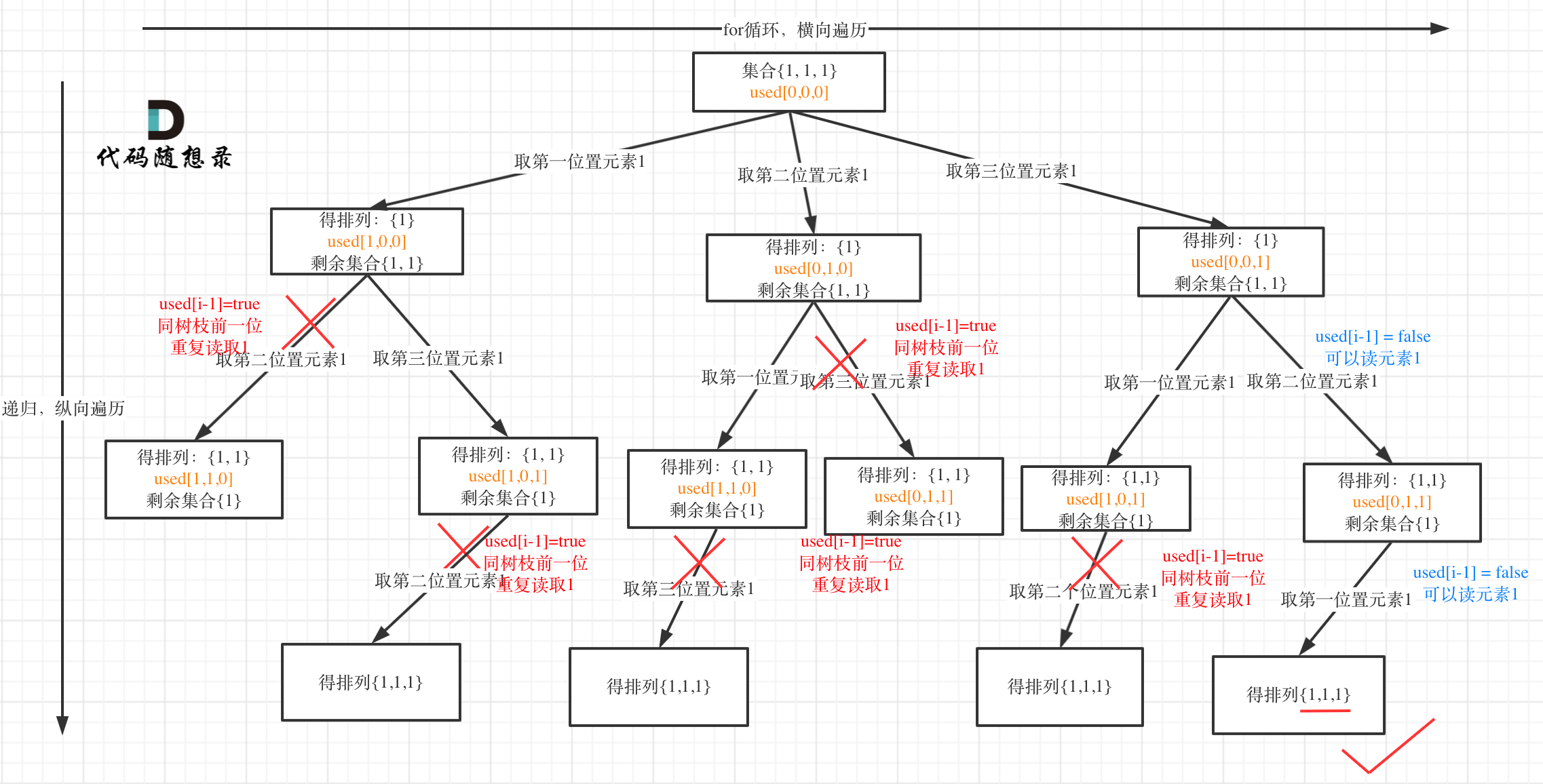
树层上对前一位去重非常彻底,效率很高,树枝上对前一位去重虽然最后可以得到答案,但是做了很多无用搜索。
总结
如果我们在去重操作中不写这个条件,!used[i - 1] 或者 used[i - 1],直接写成:
if (i > 0 && nums[i] == nums[i - 1]) continue; 其实并不行,一定要加上 used[i - 1] == false 或者 used[i - 1] == true,因为 used[i - 1] 要一直是 true 或者一直是 false 才可以,而不是一会是 true 一会又是 false, 所以这个条件要写上。