

二叉树搜索树的最小绝对值差
利用二叉搜素树的特性
这里的思路与验证二叉搜索树其实是一致的,需要明确的是,二叉搜索树进行中序遍历的时候一定是一个递增的序列。
所以可以利用这个特性来求解最小绝对值差。
void traversal(TreeNode* node, vector<int>& nums) { // 中序遍历搜索二叉树,返回有序数组
if (!node) return;
if (node->left) traversal(node->left, nums); // 左
nums.push_back(node->val); // 中
if (node->right) traversal(node->right, nums); // 右
}
int getMinimumDifference(TreeNode* root) {
vector<int> vec;
if (!root) return 0;
traversal(root, vec);
// 求数组中的最小绝对值差
int ans = INT_MAX;
for (int i = 1; i < vec.size(); i++) {
int temp = abs(vec[i] - vec[i - 1]); // -> temp = min(temp, abs(vec[i] - vec[i - 1]));
if (temp < ans) ans = temp;
}
return ans;
}二叉搜索树的双指针遍历
这里在遍历的时候可以定义两个指针 cur 和 pre,cur 指向当前节点,pre 指向前一个节点。
然后在遍历的时候,cur 和 pre 之间的差值就是当前节点和前一个节点之间的差值。
int ans = INT_MAX; // 定义全局变量 ans,初始值为 INT_MAX
void traversal (TreeNode* cur, TreeNode*& pre) { // 这里 pre 是引用类型
if (!cur) return;
if (cur->left) traversal(cur->left, pre);
if (pre) { // 当pre为空的时候不会进行这一步
ans = min(ans, cur->val - pre->val); // 计算差值
}
pre = cur; // 更新pre指针
if (cur->right) traversal(cur->right, pre);
}
int getMinimumDifference(TreeNode* root) {
if (!root) return 0;
TreeNode *pre = nullptr;
traversal(root, pre);
return ans;
} 为什么pre要使用引用类型
cur的作用cur是当前递归函数正在处理的节点。它是一个普通的指针,因为每次递归调用时,cur都会被赋值为树中的下一个节点(左子节点或右子节点)。递归调用时,cur的值会被复制到新的栈帧中,因此不需要使用引用。
pre的作用pre是用来记录当前节点的前一个节点,以便计算两个节点值之间的差值。由于递归函数需要在不同的递归栈帧之间共享和更新pre的值,因此必须使用引用类型TreeNode*&。如果
pre不使用引用类型,而是普通指针TreeNode*,那么在递归调用中对pre的修改只会影响当前栈帧的局部变量,而不会影响外层递归栈帧中的pre。这会导致pre无法正确地在整个递归过程中保持更新。
- 为什么 cur 不需要引用
cur是递归函数的输入参数,每次递归调用时都会传入新的节点值。即使不使用引用,递归调用时cur的值也会正确传递到下一个栈帧中,因此不需要用引用
二叉搜索树中的众数
这里直观的思路是使用一个哈希表来存储每个节点的值和出现的次数,然后遍历哈希表,找出出现次数最多的值。
首先递归遍历二叉树(何种遍历顺序都无所谓),统计每个节点的值出现的次数,存入 map 中。
之后遍历 map,找出出现次数最多的值。
这里就不多介绍这种一般的解法了。
下面使用和二叉树中的双指针遍历一样的思路,使用 pre 和 cur 来遍历二叉树。可以遍历两遍二叉树,一遍遍历找出最大值,另一遍遍历找出众数。
不过这里介绍的还是只遍历一次二叉树的写法。
int count = 0; // 定义全局变量 count,初始值为 0
int maxCount = 0; // 定义全局变量 maxCount,初始值为 0
vector<int> ans; // 定义全局变量 ans,存储众数
void traversal(TreeNode* cur, TreeNode*& pre) {
if (!cur) return;
if (cur->left) traversal(cur->left, pre); // 左
if (!pre) count = 1; // 当遍历到第一个节点时,还没有pre此时count就直接等于1
else if (cur->val == pre->val) count++; // 当前后节点的数值相等时,count加1
else count = 1; // 否则,前后数值不相等了,重新让count等于1
pre = cur; // 赋值pre指针
if (count > maxCount) { // 当count的值大于maxCount时
maxCount = count; // 更新maxCount
ans.clear(); // 此时因为更新maxCount,结果集中的就不是出现最多的数了,因为要清空结果集
ans.push_back(cur->val); // 将新的值放入结果集中
} else if (count == maxCount) { // 否则当count和maxCount相等时
ans.push_back(cur->val); // 加入结果集
}
if (cur->right) traversal(cur->right, pre); // 右
return;
}
vector<int> findMode(TreeNode* root) {
if (!root) return ans;
TreeNode *pre = nullptr;
traversal(root, pre);
return ans;
}更新结果集频率
count大于maxCount的时候,不仅要更新maxCount,而且要清空结果集,因为结果集之前的元素都失效了。
二叉树的最近公共祖先
这里涉及到二叉树的一个自底向上处理的一个思路,当要向上处理的时候,可以使用后序遍历的方式来解决。
在查找公共祖先的时候有以下的几种情况:
- 如果找到一个节点,发现左子树出现结点
p,右子树出现节点q,或者左子树出现结点q,右子树出现节点p,那么该节点就是节点p和q的最近公共祖先
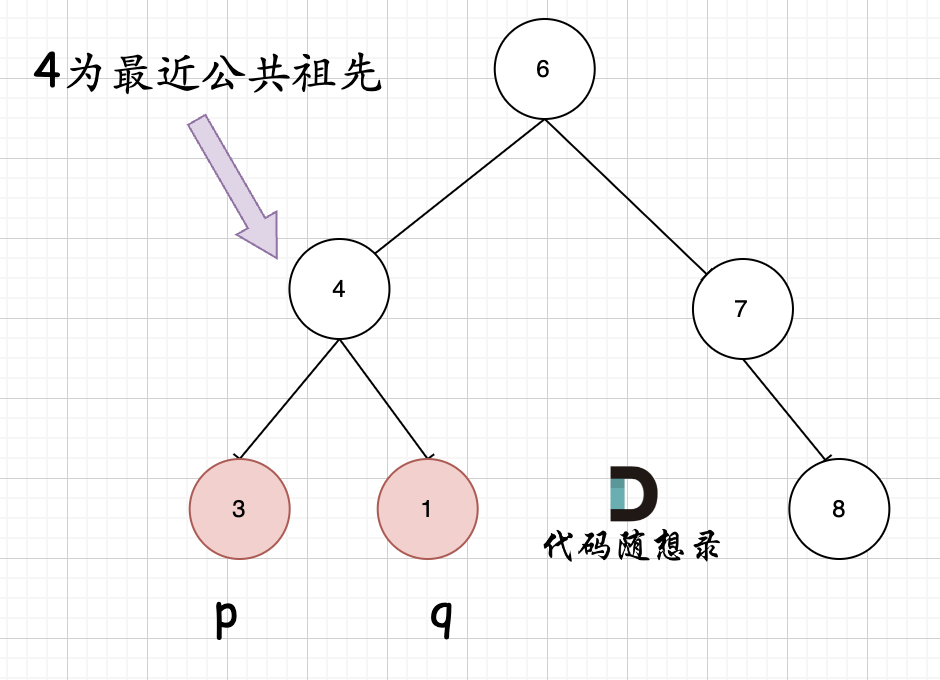
- 节点本身
p(q),它拥有一个子孙节点q(p), 那么该节点就是节点p和q的最近公共祖先
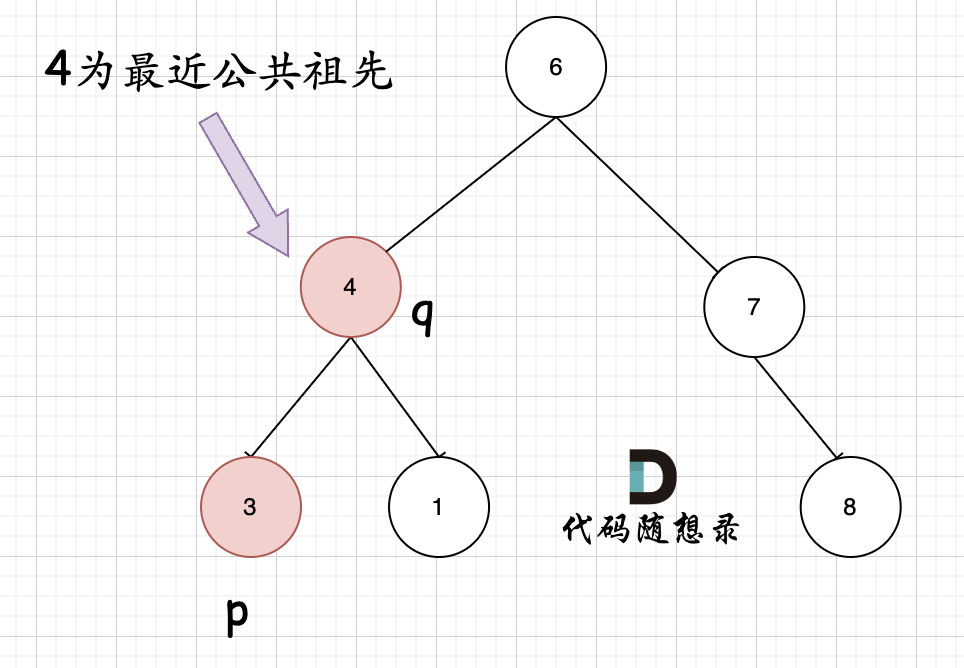
判断的逻辑是:如果递归遍历遇到 q,就将 q 返回,遇到 p 就将 p 返回,那么如果左右子树的返回值都不为空,说明此时的中节点,一定是 q 和 p 的最近祖先。
其实情况一和情况二代码实现过程都是一样的,也可以说,实现情况一的逻辑,顺便包含了情况二。因为遇到 q 或者 p 就返回,这样也包含了 q 或者 p 本身就是公共祖先的情况。
完整的代码如下:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
// 如果当前节点为空,说明递归到底了,返回空
if (root == nullptr) {
return nullptr;
}
// 如果当前节点就是 p 或 q,那么说明找到了其中一个
// 直接返回这个节点(不再继续往下找)
if (root == p || root == q) {
return root;
}
// 在左子树中递归查找 p 和 q
TreeNode* leftResult = lowestCommonAncestor(root->left, p, q);
// 在右子树中递归查找 p 和 q
TreeNode* rightResult = lowestCommonAncestor(root->right, p, q);
// 情况一:如果左子树和右子树都不为空,说明 p 和 q 分别出现在两边
// 此时当前 root 就是最近公共祖先
if (leftResult != nullptr && rightResult != nullptr) {
return root;
}
// 情况二:如果只有左子树不为空,说明 p 和 q 都在左边
if (leftResult != nullptr) {
return leftResult;
}
// 情况三:如果只有右子树不为空,说明 p 和 q 都在右边
if (rightResult != nullptr) {
return rightResult;
}
// 情况四:左右子树都没找到,返回空
return nullptr;
}求最小公共祖先,需要从底向上遍历,那么二叉树,只能通过后序遍历(即:回溯)实现从底向上的遍历方式。
在回溯的过程中,必然要遍历整棵二叉树,即使已经找到结果了,依然要把其他节点遍历完,因为要使用递归函数的返回值(也就是代码中的
left和right)做逻辑判断。要理解如果返回值
left为空,right不为空为什么要返回right,为什么可以用返回right传给上一层结果。
总结
在确定单层递归逻辑的时候,要关注函数是否有返回值,是因为回溯的过程需要递归函数的返回值做判断,也可以从是否要遍历整棵树来做判断。
二叉树-递归函数返回值是否需要返回值,取决于是否需要从子树返回“信息”给父节点来“做决策”。 如果要“从子树拿信息回来” —— 要返回值; 如果只是“走一遍树做操作” —— 不需要返回值。
问题类型 是否需要返回值 典型例子 查找、判断、返回某个节点 是 最近公共祖先、查找值、路径求和 纯遍历或修改树结构 否 遍历打印、翻转、修改值
如果递归函数有返回值,如何区分要搜索一条边,还是搜索整个树呢?
是否遍历整个树,取决于是否需要从“多个子树中综合信息”,还是在**某一条路径上找到目标后立刻返回,不再继续搜索。
- 搜索一条边(路径)的写法:
if (递归函数(root->left)) return true;
if (递归函数(root->right)) return true;
return false;- 搜索整个树写法:
auto left = 递归函数(root->left); // 左子树递归
auto right = 递归函数(root->right); // 右子树递归
// 根据 left 和 right 的返回值判断逻辑
return 结果;