

二叉搜索树的最近公共祖先
二叉搜索树(BST)的特性,对于任意一个节点 root:
左子树所有值 <
root->val右子树所有值 >
root->val
所以根据二叉搜索树的这个特性,我们可以有以下的思路:
我们从根节点 root 开始,比较 p 和 q 的值:
情况一:
p.val<root.val&&q.val<root.val→ 说明
p和q都在左子树 → 往左走情况二:
p.val>root.val&&q.val>root.val→ 说明
p和q都在右子树 → 往右走情况三:
p和q分别在两边→ 当前
root就是最近公共祖先
为什么当p和q分别在两边时,当前root就是最近公共祖先在 BST 中,每个节点都有如下性质:
所有 左子树节点 < 当前节点值
所有 右子树节点 > 当前节点值
假设我们在当前节点
root发现:
p < root->val&&q > root->val或者相反说明它们分布在两边
→ 如果再往上走一层,
p和q仍然是它的子孙,但距离更远→ 如果再往下走一层,那一边就不包含两个节点了
所以,“第一次分叉的地方”一定是最近公共祖先。
因此我们可以写出以下的代码:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
// 如果 p 和 q 都比 root 小,说明 LCA 在左子树
if (p->val < root->val && q->val < root->val) {
return lowestCommonAncestor(root->left, p, q);
}
// 如果 p 和 q 都比 root 大,说明 LCA 在右子树
else if (p->val > root->val && q->val > root->val) {
return lowestCommonAncestor(root->right, p, q);
}
// 否则,说明分布在两边,当前 root 就是最近公共祖先
else {
return root;
}
}二叉搜索树中的插入操作
我们要做的事很简单:
从根节点出发,根据大小关系,递归或迭代地走到合适的位置,然后插入新节点。
当前节点不为空:
如果
val < root->val,递归插入到左子树如果
val > root->val,递归插入到右子树
当前节点为空(走到叶子外部了):
- 创建新节点并返回
所以可以写出以下的代码:
TreeNode* insertIntoBST(TreeNode* root, int val) {
// 如果当前节点为空,说明找到了插入位置
if (root == nullptr) {
return new TreeNode(val);
}
// 如果插入值小于当前节点,插入到左子树
if (val < root->val) {
root->left = insertIntoBST(root->left, val);
}
// 如果插入值大于当前节点,插入到右子树
else if (val > root->val) {
root->right = insertIntoBST(root->right, val);
}
// 返回当前节点(整棵树最终返回 root)
return root;
}为什么不需要“重新排序”或者“重构整棵树”,只需要在正确的位置插入就行?我们在“每一步决策”里都遵守了 BST 的基本规则:
如果
val< 当前节点 → 插入左子树如果
val> 当前节点 → 插入右子树这样保证了“局部有序性”:插入后,每一层都仍然满足 BST 条件,再加上 BST 是递归结构,每个子树也是一棵 BST,所以这种局部有序性会自动延续下去。
换句话说,只要遵守 “小左大右” 的递归结构,BST 的性质就保持住了
二叉树中的删除操作
相比插入节点相比,删除的逻辑更复杂一些。
递归函数的终止条件是:当当前节点为空时,返回空指针。
if (root == nullptr) return nullptr;这里我们大致可以分为三种情况,也可以看作是五种:
未找到节点,直接返回空指针
删除的节点是叶子节点,直接删除
仅有右子树存在,右子树补位
仅有左子树存在,左子树补位
左右子树都存在,找到右子树的最小节点(后继),将当前节点的左子树接到它的左侧
这里的最小节点是指:在右子树中,最左边的节点(也就是最小值)
之后将当前节点的左子树接到它的左侧
然后返回当前节点的右子树为新的根节点
以下为第五种情况的动画演示
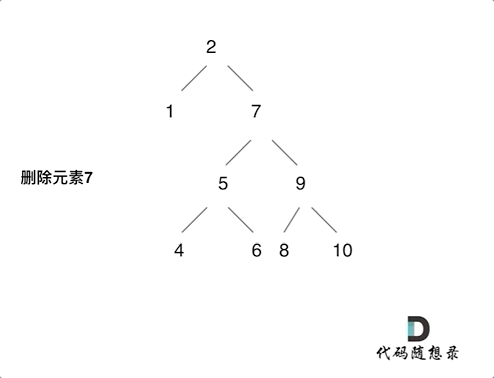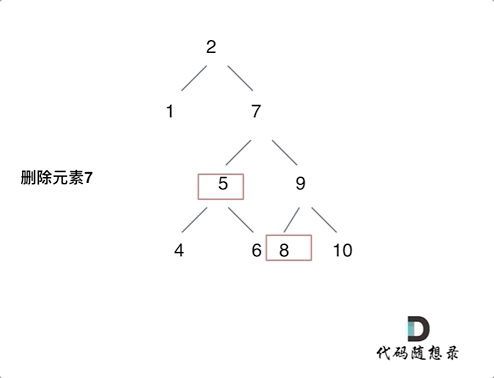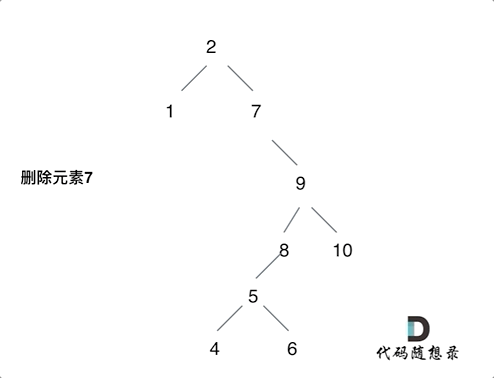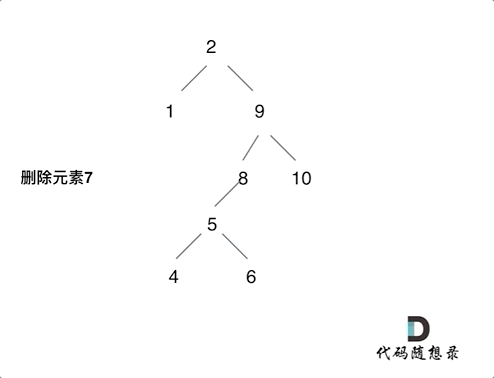
根据上面的逻辑,我们可以写出以下的代码:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return nullptr; // 情况 1:未找到节点,直接返回空
if (key < root->val) {
// 说明目标值在左子树中,递归删除
root->left = deleteNode(root->left, key);
}
else if (key > root->val) {
// 说明目标值在右子树中,递归删除
root->right = deleteNode(root->right, key);
}
else {
// 情况 2~5:找到目标节点,开始分类处理
// 情况 2:叶子节点,直接删除
if (root->left == nullptr && root->right == nullptr) {
delete root;
return nullptr;
}
// 情况 3:仅右子树存在,右子树补位
else if (root->left == nullptr) {
TreeNode* retNode = root->right;
delete root;
return retNode;
}
// 情况 4:仅左子树存在,左子树补位
else if (root->right == nullptr) {
TreeNode* retNode = root->left;
delete root;
return retNode;
}
// 情况 5:左右子树都存在
// 找到右子树的最小节点(后继),将当前节点的左子树接到它的左侧
else {
TreeNode* successor = findMin(root->right);
successor->left = root->left;
TreeNode* temp = root;
root = root->right; // 把 root->right 提上来作为新的根
delete temp;
return root;
}
}
return root;
}
// 辅助函数:查找某个子树的最小节点(一直往左走)
TreeNode* findMin(TreeNode* node) {
while (node->left != nullptr) {
node = node->left;
}
return node;
}总结
操作二叉搜索树的关键在于始终遵循“小于放左,大于放右”的结构规律。无论是查找、插入还是删除,本质都是在利用这一规则不断缩小问题规模。
二叉搜索树添加节点只需要在叶子上添加就可以的,不涉及到结构的调整,而删除节点操作涉及到结构的调整。